

鞭牛士报道,11月9日消息,据外电报道,根据Ziff Davis 的一项新研究,谷歌、OpenAI 和 Meta 等人工智能巨头在训练大型语言模型时更加重视来自知名新闻来源的内容。
这一发现可以帮助公众了解聊天机器人从哪里获取信息,并为 Ziff Davis、芝加哥论坛报、新闻集团和纽约时报等媒体公司在寻求版权保护或支付被人工智能吞噬的材料时提供更多筹码。
研究指出:我们的研究表明,关键的AI培训数据集主要由新闻和媒体网站商业出版商拥有的高质量内容组成。在AI技术发展短暂的历史上,主要的AI公司已在培训最重要的AI时优先考虑了这些内容。
Ziff Davis 是 PCMag 的母公司。这项研究由该公司首席 AI 律师 George Wukoson 和首席技术官 Joey Fortuna 进行。它检查了 AI 公司承认使用的数据集的开源副本,包括 Common Crawl、C4、OpenWebText 和 OpenWebText2。
OpenAI 承认会对其认为高质量的数据集赋予更多权重,包括新闻媒体、受版权保护的书籍以及 Reddit 热门帖子中嵌入的链接。这是一种对 LLM 从网络上抓取的所有内容进行排名的方式,目的是为用户提供更好的答案。
例如,尽管 WebText2 只占 3.8% 的 token,但它在训练 GPT-3 时赋予了它 22% 的权重。WebText2 中嵌入的近 13.5% 的 URL 来自 15 家顶级媒体出版商,其中包括新闻集团、纽约时报、Gannett、Ziff Davis、Vox Media、Axel Springer、Alden Capital、赫斯特、华盛顿邮报、BuzzFeed、Future、IAC 和 Bustle。
数据集的内容也会随时间而变化。例如,OpenAI 在 OpenWebText 中高度重视《华盛顿邮报》的内容,但在 OpenWebText2 发布后,其重要性有所降低。
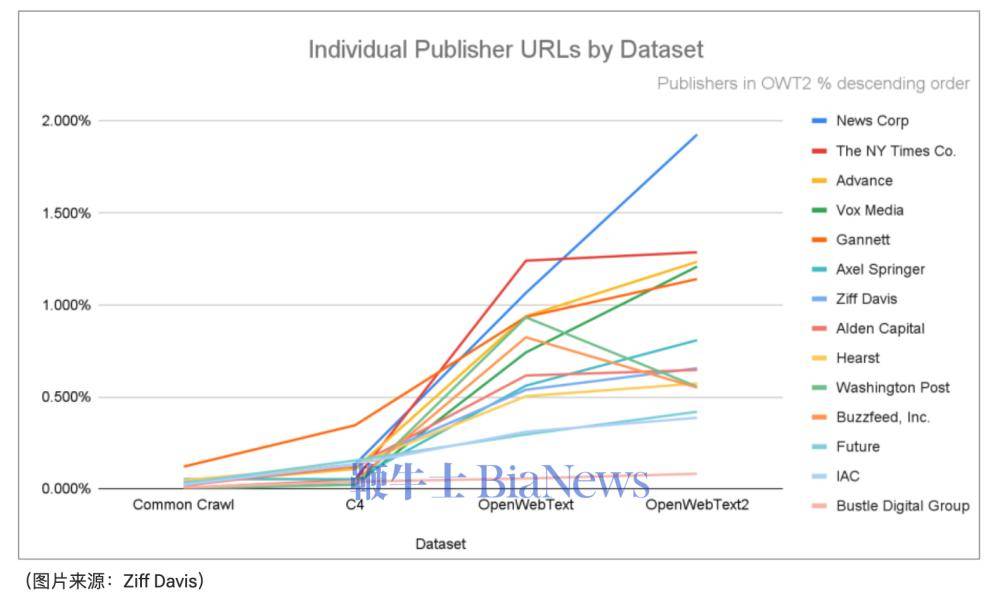
齐夫·戴维斯 (Ziff Davis) 表示,研究结果量化了新闻媒体对人工智能聊天机器人未来的重要性,而且新闻媒体无需为此付费。这种长期利用优质出版商内容(对 LLM 公司来说利润丰厚)[意味着] 失去了一些全球估值最高的公司的许可收入。
如果不为内容付费,出版商可能会破产,从而威胁人工智能时代优质信息的持续流动。
据路透社报道,此前,一名联邦法官驳回了 Raw Story 和 AlterNet 对 OpenAI 提起的诉讼,该诉讼称,OpenAI 未经许可使用其内容培训法学硕士。 《纽约时报》提起的相关案件仍在审理中。OpenAI 还与许多顶级媒体公司签署了许可协议。
OpenAI 最新推出的产品ChatGPT 搜索现在除了总结其中的内容外,还引用了部分来源。返回搜狐,查看更多
责任编辑:







 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号